Table of Contents
Open Table of Contents
Design Goals
Rua 是 Lua 的 Rust 实现, ruac 是其编译器部分, 负责从源代码生成 lua bytecode. ruac 的设计目标包含以下几点:
-
Make Software Engineering Great Again
如果读者对 Clang 和 GCC 有所了解, 或者曾经尝试过基于他们做 Compiler Tools, 那应该很容易理解我在说什么. 将编译器的各个组件实现为 API 集合有利于复用已有的工作, 并能降低后续开发和维护成本. 我想 ruac 与 luac 最大的不同就在于此. ruac 会是是一系列可重用, 性能说得过去的 API 集合. 我希望它最终是”软件工程的胜利”, 最好能有着跟Roslyn一样好看的 API. -
Keep compatible with luac at-best-effort but 64-bit platform only
与官方的 luac 保持兼容, 这是一个必要的但同时也非常艰巨的任务. 因为完整的兼容性支持需要从无标准规定的 luac 实现中生扒出来标准然后在另一个语言中实现这份标准, 而没有兼容性意味着 ruac 将会是一个玩具. 『尽最大努力』则是 ruac 兼容性要求优先级要比 VM 兼容性的优先级低, 在后者达成兼容性目标之前, 前者不会得到保证. 最后, ruac 假定工作于 64 位平台上, 不会像 luac 一样提供对 32 位平台的支持. -
An Configurable Optimizer
优化器将作为单独的一部分工作在 ruac 中端部分. 根据上一条对兼容性的要求, 优化器至少会有 lua 5.4 引入的常量折叠. 其他额外添加的部分则是可配置的. 至于优化器具体的功能列表取决于在写到那一章时我能学会并能够实现哪些功能在 Overview 阶段还不能确定, 激进的优化导致行为与标准 Lua 不一致也是可能的. -
Balance between high perfomance and low memory use
说好听点叫『高性能和低内存占用之间的平衡』, 说直白点就是我还没把握以”性能最快同时内存最低”的方式打开 Rust, 只能希望 ruac 跑的别太慢, 内存占用别太离谱. 反应到具体的设计和代码上, 其要求差不多是尽量少地遍历树以及 “不要无脑Rc::clone仿佛生命周期残疾, 或者到处Box<dyn Trat>如同在写 OO Language” 这一级别的. 或者说, 尽量遵守良好的 Rust 语言实践. 我想结果上应该不会有太差的性能.
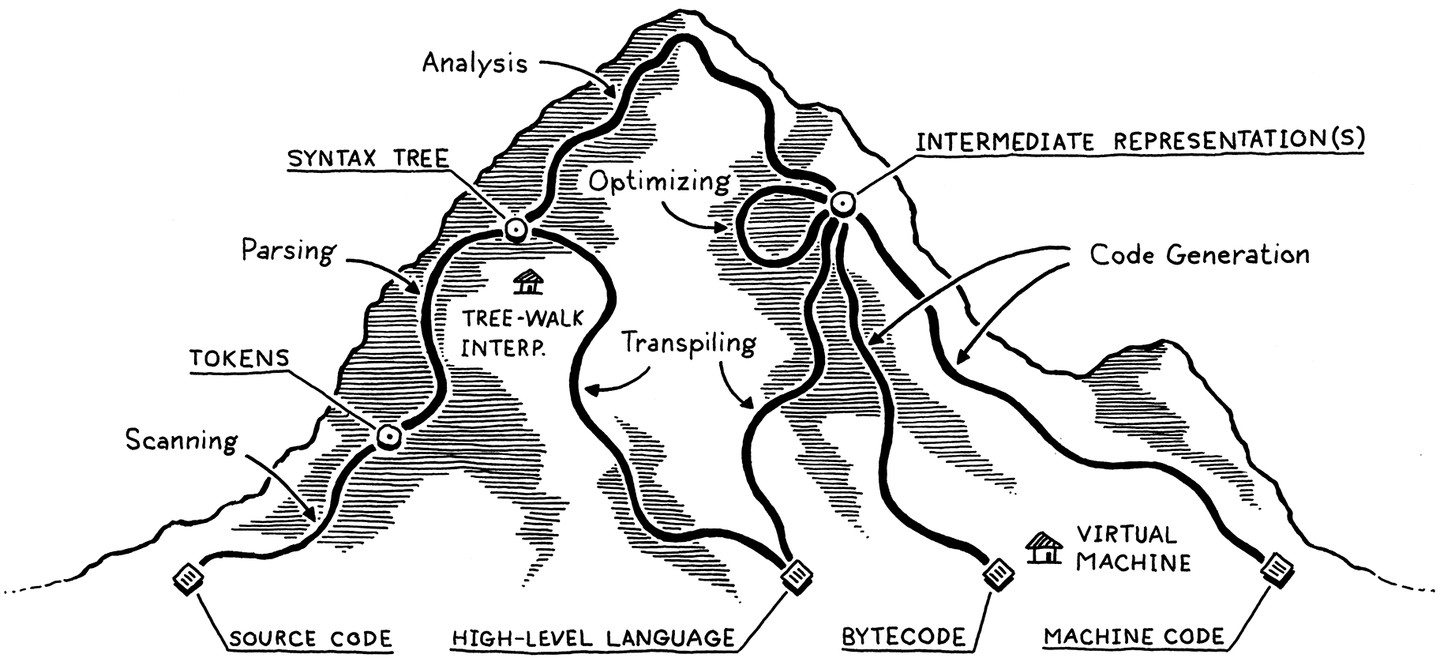
Compiler Overview
Official Implementation: Luac Overview
在我的理解中, luac 其实是 lua VM 的一部分, 因为使用前者需要先创建后者, 前者在工作时候使用的内存以及创建的对象 (Lua Obeject), 也是从 VM 的 GC 堆上分配出来的. luac 工作时单趟 (Single Pass) 编译, 只扫描一次源代码, 词法分析, 语法分析, 代码生成同时进行. 这样的好处是更快, 代码体积更小. 缺点就是糅合的代码无法复用 Compiler 的某一部分做额外工作, 也无法做多趟配合才能完成的优化功能.
在 lua 诞生的年代, 内存还是一种需要节约的资源, 做出如今看来美中不足(此处应当标记为存疑或作者主观意见)的取舍是合情合理的. 至于其他编译器应该关注的指标, 如代码生成质量, 编译时间等, 因为要么是与指令集强相关而我学识尚浅无法评价, 要么是我并非专业用户使用经验不足所以评价没有意义. 在我以初学者角度看来, 经过了三十年的迭代和现实世界的考验, 整体上 luac 的实现相当精巧, 没有明显的不足.
具体到各个部分, 按照编译流程来说 luac 中值得关注的点有如下部分:
-
Zio
luac 不会一次性将源代码读入内存中以连续的字符串存储, 其使用名为 Zio 的结构作为输入文件的缓冲, 性质与 C++ 中的 fstream 类似. 这样减少了 Bad Path 上错误发生时的代价, 也可以在解析大文件时减小运行时内存占用. 我推测这可能是 zipped io 的缩写. -
LexState
luac 的词法分析器, 支持 look ahead 2 tokens 的同时还提供行列信息. 所有的保留字都在词法分析阶段解析完毕, 不支持软关键字 (Soft Keywords), 不支持 utf8 字符但是允许字符串字面量中存在 utf8 code point. -
FuncState
luac 的语法分析器实际上是 FuncState 结构体, 该结构体内部维护了符号表和跳转表等全部的编译时信息. 对外暴露的接口只有luaY_parser方法. parse 阶段不产生语法树, 直接进行字节码生成, 所以 parse 的产物与通常的 CodeGen 阶段产物一致, 是能够直接被 VM 加载然后执行的函数原型 (Proto). -
ExprDesc / BlockCnt
前者用于对表达式 parse 的同时进行代码生成. 后者维护的词法作用域, 处理 Variable Shadow 和 循环块 等信息. -
Proto
用于描述函数的原型体, 或者说是 Compile 产物的内存表现形式. 整个 Lua 源文件会被当作一个匿名的函数进行解析而产生 Proto. 这样的一段源代码也被称为 Chunk. -
Error Handling
编译时的错误处理与 lua VM 中对其他任何的错误处理完全一致, 将错误转化为描述原因字符串放在栈上, 进入通用的错误处理模式. 因为错误是无类型的, 这可能让捕获错误和自动错误恢复不容易进行. -
Chunk Dumper
将编译产物表现为文本或者二进制形式的配套基础设施.
以上这些概念都能在 ruac 中找到对应的概念, 不了解以上概念不影响后续文章阅读.
CLIR Implementation: Ruac Overview
而对于 ruac 来说, 其值得关注的点基本在 Design Goals 中描述过了, 将这些目标体现在设计上则可以描述为以下几点:
-
Lexer
ruac 词法分析器部分, 其底层是通过一个 Scanner 处理源文件上的 Input Char Iterator. 得益于 Rust 内建的对 utf8 支持, 所以 ruac 天生支持 utf8 源代码. 词法分析器对外表现为一个可重复调用获取下一个 Token 的类似生成器的结构. 而非一次性生成所有的 Token Stream 再进行 parse 工作. 这也是为了降低错误发生时的沉没成本, 至于其他方面与 luac 的词法分析器没有明显差异. -
Parser
与 luac 一致, 词法分析器被包括在 parser 中, 与带缓冲的 luac 不同, Parser 的输入只能是 String 类型, 所以要求其把源文件所有内容一次性读入内存再进行后续处理. 解析器部分只对外暴露parse方法. parse 的产物是语法树的根 (root), 允许后续流程对树进行操作. Parser 被实现为手写的递归下降 LL(2) 分析器. -
Abstract Syntax Tree / Pass Trait
分别是”语法树”的定义和”趟”的定义. 前者是 Lua 源代码在 Compiler 内存中的中间表示 (IR, Intermidiate Represetation), 并且附带了源文件信息, 后者是优化器和代码生成的工作接口. 语法树定义的好和坏几乎直接影响 Compiler 开发难度. 由于 Lua 语言简单, ruac 只包括单层树状 IR. -
Code Generation / Proto
代码生成阶段, 其中包含 ExprStatus 和 Generation Context 用于辅助代码生成阶段优化. CodeGen 产生的指令在内存中的形式和落盘后的二进制形式均与 luac 完全一致. 直到 CodeGen 的 编译阶段均无需 VM 参与, 产生的 Lua 值会被存放于 Rust 程序的堆空间中, 待 Proto 被 VM 托管时会被转移到 VM 的 GC 堆上. -
Error Handling
ruac 的错误被描述为 Rust 中的具值枚举 (Enum), 以支持对错误进行匹配和处理, 使用Result<T, StaticErr>类型添加到各个接口中.StaticErr是无需 VM 参与即可发现的错误, 或者说编译时可发现的错误, 既包括语法, 语义错误, 也包含代码生成阶段的寄存器溢出等编译器后端错误. -
AST Dumper / Chunk Dumper
前者是将 Lua 源文件语法树导出为文本形式. 是 ruac 额外附带的套件, 后者将 Proto Dump 为二进制形式或文本形式, 输出与标准 luac 类似, 在文本形式下附带额外的信息.
Dev Rhythm
根据以往观察到以及体验过的『立下 flag 但因为开发中缺少正反馈最终不得不鸽了』的实践经验, 在开一个新坑并尝试填上的过程中, 优先构建可以运行的原型并在此基础上逐步添加功能是较好的开发节奏.
ruac 整体上不会违反这条原则, 但考虑到对 ruac 的前端和中端部分有十足的信心, 所以在 Tokenizer, Parser 这一局部, 我会以 F2+A 的方式构建出完整的功能, 不必在将来回头检查对语法的支持或者改某个 Corner Case 的错误. 后端代码生成部分则是按照敏捷模式, 优先支持少数指令并且不考虑优化. 随着 VM 对指令集的支持而逐步完善并添加优化. 在这个过程中一旦前, 中, 后端的某一部分设计稳定, 我会暂停新功能的开发转而添加与该部分有关的基础设施, 以像 Parser 一样直接做出成品的方式进行, 例如中端的常量折叠, AST Dumper, 后端的 Binary Dumper. 在某一部分的设计稳定以及配套设施均完成后, 我会将其记录在本系列内, 同时进行局部的 Code Review, 增加单元测试以及修补文档等工作.
对于开发工作本身来说, 这样的安排可以将开发工作中的关注点分离到较小的局部, 减小开发者记忆和认知的负担. 对于《CLIR》则是内容更加紧凑, 不会让相关的主题均匀分散到系列各处. 对于我自己来说还有额外的机会可以立刻进行 Design Review 以免思路和实现细节在后续开发中被忘记. 这样安排的缺点也很明显, 如果给出了一个糟糕的 AST 定义并且无法在 Parser 开工时就意识到其问题所在, 那么在发现错误之后, 完成度拉满的 Parser 反而成了负担. 我只能在希望自己运气好一点不要撞见这种情况的的同时保证: 如果真的撞见这种情况, 我会回来改掉上一段的第一句话的.